목표
VM 환경에서 하둡을 완전 분산 모드로 설치하고 Map-Reduce를 실행해보자.
준비
- VirtualBox (6.x)

- Linux distro image (Ubuntu 20.x)

VirtualBox에 Linux 설치
Part 1 - VM 만들기
- VirtualBox를 실행하고 [Ctrl + N] 혹은 [새로 만들기(N)] 버튼을 클릭

- 임의의 VM 이름 입력 (종류와 버전이 자동 선택 되는 듯), 저장 위치 지정, 종류와 버전 선택. [다음(N)] 버튼 클릭. 메모리 크기를 지정. 여기서는 2gb 설장함. [다음(N)].


- 지금 [새 가상 하드 디스크 만들기(C)] 선택, [다음(N)]. [VDI(VirtualBox 디스크 이미지)] 선택, [다음(N)].


- 설명을 읽어보고 선택. 여기서는 동적 할당 선택함. [다음(N)]. 하드 디스크 크기 설정. 여기서는 30gb 설정함. [만들기].
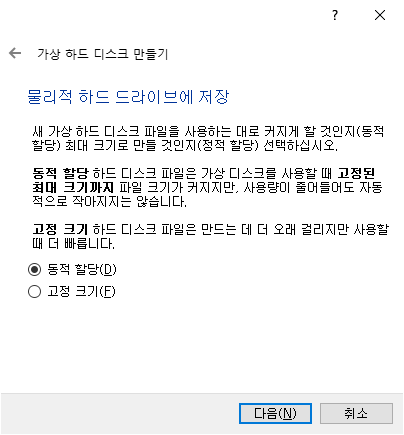

- 완료.

Part 2 - Linux 설치
- 더블 클릭. 시동 디스크 선택 창에서 폴더 버튼 클릭.

- [추가(A)] -> Linux image 파일 열기 -> 선택 -> 시작을 누르면 부팅됨.

- 언어를 선택하고 Ubuntu 설치, 키보드 레이아웃 설정.
* (여기서 아래와 같이 버튼이 안보일 경우: VM을 종료하고 VirtualBox에서 VM을 클릭하고,
[설정 -> 디스플레이 -> 그래픽 컨트롤러] 를 VMSVGA에서 다른 것으로 변경하고 다시 실행하면 화면 크기를 조정하면 버튼을 볼 수 있음. *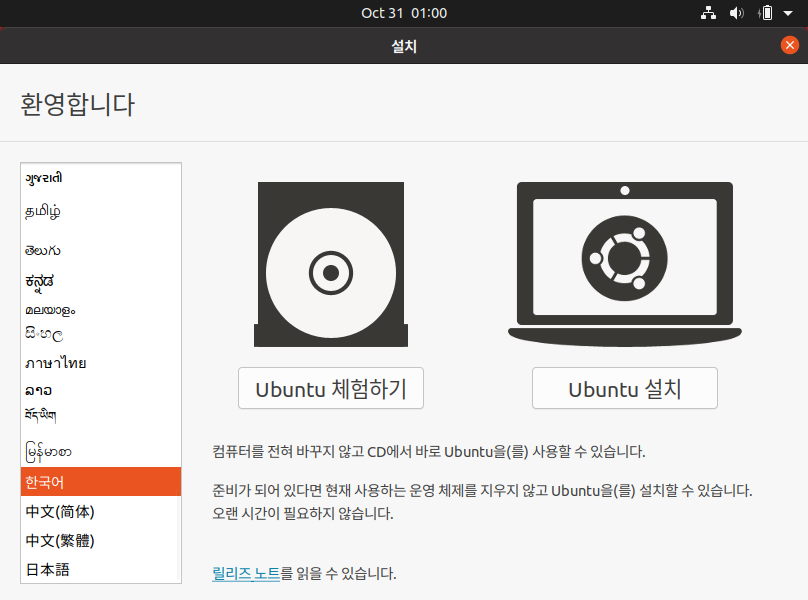

- 이후 적절하게 설정하면서 설치 진행.
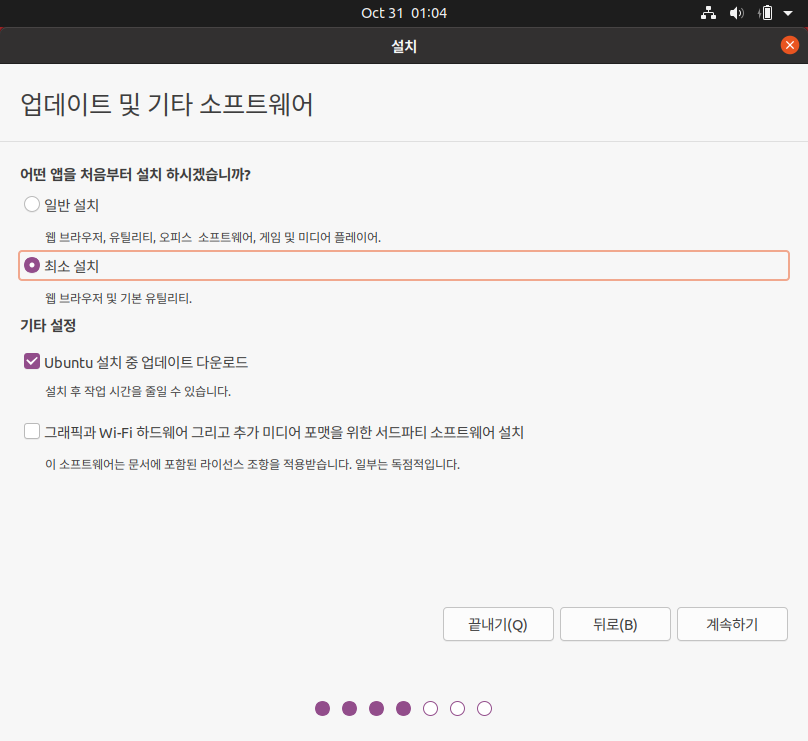

- 계속하기.


- 사용자 이름은 hadoop으로 해주고 계속하기.

- 드디어 설치가 되는 중. 본인 컴퓨터에서는 꽤 오랜 시간이 걸렸다. 커피를 마시면서 기다린다.

- 다시 시작 후 엔터.


- 로그인 후, [Ctrl + Alt + T]로 터미널 실행.


# 하둡 설치는 다음 장으로
'DATA SCIENCE > HADOOP ECOSYSTEMS' 카테고리의 다른 글
| Hadoop 3 완전 분산 모드 설치 - 2 (Hadoop 설치 & MapReduce) (0) | 2021.10.31 |
|---|---|
| [Hbase] Hbase ? (0) | 2021.10.13 |


댓글