Hbase
Master Server/ Region Server
Master (HDFS-Namenode): Create/Delete table, 서버간 로드밸런싱, Zookeeper를 통해 각 Region Server를 할당하고 작업 지시, Region Server 위치를 알려줌
- Hbase client 요청 -> Zookeeper -> root region server -> meta region server -> 요청된 data region server
- region 위치 cache에 저장 -> cache의 위치가 적절하지 않으면 region 재배치, cache 업데이트
Region Server (HDFS-Datanode): CRUD, WAL, MemStore, Hfile, Block Cache
- Region 관리, 호스팅, 자동 분할
- Client와 직접 커뮤니케이션
Zookeeper: 마스터 서버가 사용 가능한 서버와 통신, 정상동작 감지, Master의 동작도 감지하고, 정상적으로 작동하지 않으면 비활성화 되어있던 다른 Master를 활성화
- META 서버의 path를 관리하며, 어떤 클라이언트든지 Region을 검색할 수 있게 해줌
Hbase는 Column-Family 기반의 NoSQL 데이터베이스.
Row key를 기준으로(index) 각 Column-Family:Column = Value를 관리함. -> Row key 설계가 중요
유연하게 Column을 추가할 수 있다.
HDFS 위에서 동작.
vs RDBMS
RDBMS는 스키마를 미리 정의하고 정규화된 테이블간 join을 통해 데이터를 표현.
특정 테이블에 추가적인 Column이 필요할 경우 스키마를 재정의하고 컬럼을 추가한 후 입력하고 관계역시 정의해주어야 한다.
RDBMS는 Null 값이 데이터가 존재하는 Column 사이에 존재한다면 1Byte의 크기를 가져서 저장 효율이 떨어질 수 있다.
Hbase 구조
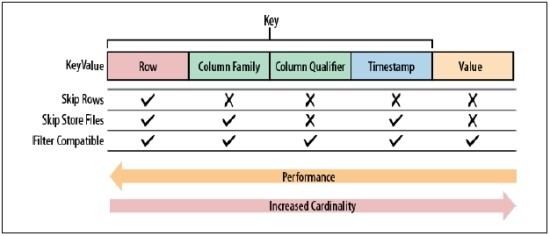
Table, Row, Column Family, Column Qualifier, Timestamp, Value(Cell)
Data 저장 시 행은 Row key 단위로, 열은 Column Family 단위로 나뉘어져서 저장
-> Row key는 Region을 나누는 단위, Column Family는 File을 나누는 단위
-> Column Family 단위로 나누어서 저장하므로 Scan 시 Column Family 지정하면 조회 성능 올라감.
Hbase 동작
- META 서버에서 목표 Region이 있는 Region Server 확인.
Write
- Client가 데이터를 쓰기 전에 Region Server를 통해 Region과 통신. WAL 파일 끝에 append
- WAL 에 쓰여진 데이터를 MemStore에 복사.
- Client에게 ACK 전송
- MemStore가 MaxSize에 이르게 되면, 가지고 있던 데이터들을 flush -> 디스크에 Hfile로 저장
Read
- Client가 읽기 요청
- Scanner는 먼저 Block Cache에서 Row Cell찾음. 최근에 읽은 Key-Value pair가 저장되어 있기 때문.
- Block Cache에 데이터가 없으면 MemStore로 이동.
- MemStore에 데이터가 없으면, Bloom Filter를 이용해서 Hfile에서 데이터를 가지고 옴.
vs RDBMS, Hbase의 성능이 좋은 이유?
대용량 데이터 처리에 있어서 join 이나 정규화, 스키마 재정의 등의 과정이 없기 때문에 (NoSQL의 특징)
확장성.
Hadoop은 데이터를 마스터로 불러와서 처리하지 않고 처리할 내용을 슬레이브로 보내서 처리함.
+ LSM-tree를 사용
Column 기반 NoSQL 장점?
동작 및 구조와 관련해서
Column-Family 기반 데이터베이스이므로, Column-Family 내의 모든 값이 함께 저장됨. 특정 열을 읽은 후에 관련있는 데이터를 검색하는데 이점이 있음.
그 외 궁금했던 부분
region: start - end 범위 지정, 해당 row key에 해당하는 값들을 정렬된 상태로 가짐
? 만약 이미 hfile이 생성된 상태에서 새로운 키가 입력되면 어떻게 되는가?
-> flush 할 때, 멤스토어에 있는 데이터를 새로운 hfile에 정렬된 상태로 쓰고, 컴팩션할 때, 정렬된 상태로 저장.
? 그러면 스캔할때 어떻게? hfile 전체 순차적 스캔?
-> Bloom Filter로 어느 파일에 있는지 판단.
NoSQL과 RDBMS의 인덱스?
RDBMS가 아닌 것들을 통틀어 NoSQL이라고 한다.
'DATA SCIENCE > HADOOP ECOSYSTEMS' 카테고리의 다른 글
| Hadoop 3 완전 분산 모드 설치 - 2 (Hadoop 설치 & MapReduce) (0) | 2021.10.31 |
|---|---|
| Hadoop 3 완전 분산 모드 설치 - 1 (VirtualBox에 Linux 설치하기) (0) | 2021.10.31 |


댓글