seq2seq
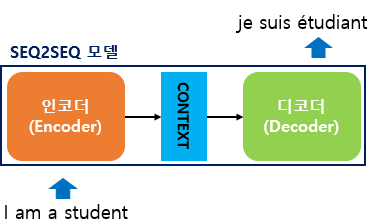
- 시계열(sequence) 데이터를 다른 시계열 데이터로 바꿔줄 수 있다. (Sequence to sequence)
- 예를 들면, 한국어를 영어나 일본어로 번역하는 작업, 음성인식 등
- seq2seq 모델은 Encoder-Decoder 모델이라고도 불린다.
구조

- 인코더는 input으로 들어간 데이터를 output으로 압축해서 표현해주고 이를 Context Vector라고 부른다.
- 디코더는 Context Vector를 새로운 시계열 데이터로 바꿔준다. (결과)
- 인코더와 디코더는 내부적으로 RNN 구조, 성능을 위해 Vanilla RNN보다는 LSTM이나 GRU로 구성됨
동작
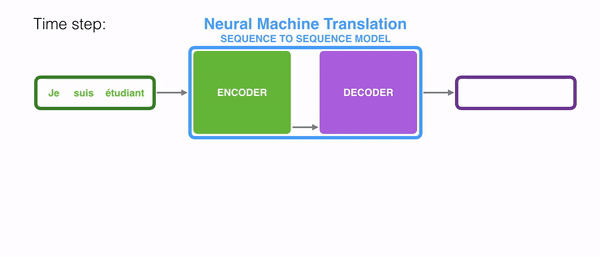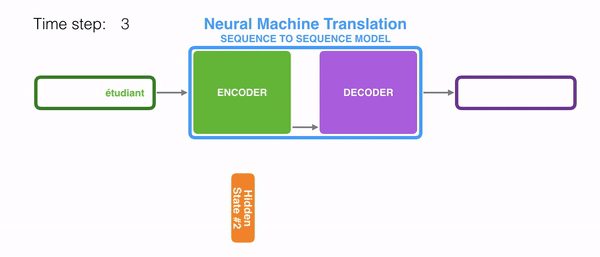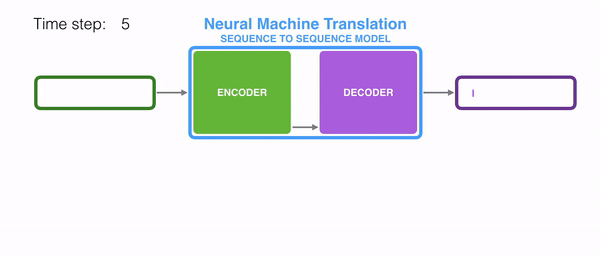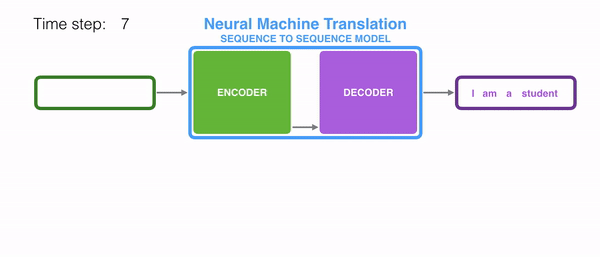
- 인코더의 output, 즉 context vector는 RNN의 마지막 hidden state 부분에 해당한다.
- -> Hidden state의 크기로 정해져있는 vector임.
- -> 길어지면 앞부분의 정보가 소실될 수 있음.

- 디코더는 context vector와 문장의 시작을 의미하는 심볼 <sos>를 받아서 첫번째 결과를 예측한다.
- 여기서 계산한 hidden state와 첫번째 결과를 input으로 다음 결과를 예측...
- 위 과정을 반복하고 문장의 끝을 의미하는 심볼 <eos>이 예측될 때까지 반복한다.
attention
- seq2seq 모델의 단점: 고정된 크기의 context vector에 모든 정보를 압축 -> 정보 손실, 입력이 길어지면 gradient vanishing 문제를 포함해 성능이 떨어짐.
- Attention = 주의, 집중, 주목
- 디코더에서 출력 단어를 예측하는 시점마다 인코더에서 모든 입력 문장을 참고한다. 단, 모두 동일한 비율로 참고하는것은 아님.
- 예측 시점에서 더 연관있는 입력에 더 집중.
- attention 함수는 Query, Keys, Values로 이루어져 있음.
- Query : 예측하고자 하는 시점의 hidden state ( 어떤 것에 얼마나 집중 할 것인가? )
- Key : 모든 시점 인코더의 hidden state ( Query에서 고려해볼 대상 )
- Values : Query와 Keys를 통해 찾아낸 값 ( 찾아낸 결과 )

디코더에서 예측할 때, 인코더의 모든 hidden state를 참고, softmax 함수를 거쳐서 어떤 부분에 얼마나 집중해야 하는지 알 수 있음. 이 데이터를 받아서 현재 디코더의 hidden state와 연결하고 softmax 함수를 통해 최종적으로 출력을 예측한다.
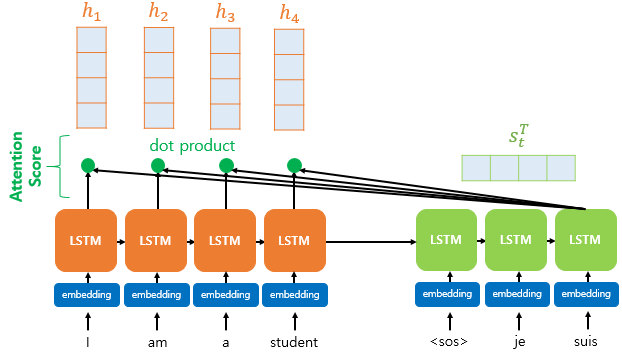
- 디코더의 hidden state와 각 인코더의 hidden state를 내적한값 즉 $ s_t^Th_i $ = attention score

- attention score의 집합 [$ s_t^Th_1, ..., s_t^Th_N $]은 softmax 함수를 거치는데, 이 각각의 값을 attention weight라고 함.
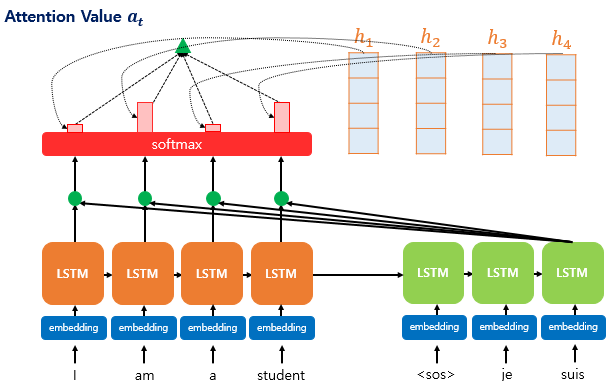
- attention weight를 각 인코더의 hidden state에 곱해서 더해준다.
- $ \sum\limits_{i=1}^{N} {w_ih_i} $ = attention value -> 어느 부분이 얼마나 중요한지 알 수 있음. 문맥을 포함하고 있다고 해서, context vector라고도 불림

- 최종 attention value를 디코더의 hidden state $h_t$와 연결.
- $= a^t$
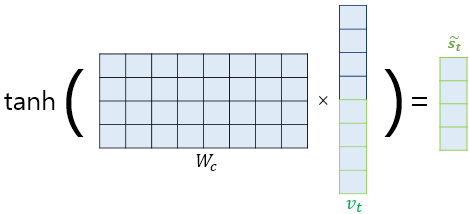
- 마지막 출력층 ( Dense - Softmax )에 가기 전에 tanh 함수를 사용해 한번 더 계산함. 결과값 $ \tilde{s_t} = tanh(Wa_t + b) $
- 출력 $ \hat{y_t} = softmax(W\tilde{s_t} + b) $
attention score functions
- dot : $ s_t^Th_i $
- scaled dot : $ s_t^Th_i/\sqrt{n} $
- general : $ s_t^TWh_i $
- concat : $ W_a^Ttanh(W_bs_t+W_ch_i)$
- location-base : $ softmax(W,s_t) $
'ML' 카테고리의 다른 글
| Basic RNN/LSTM cell implementation (0) | 2021.09.10 |
|---|---|
| RNN, LSTM ? (0) | 2021.08.16 |
| [Tensorflow 2.x] 기초 (0) | 2021.08.13 |
| AutoEncoder (0) | 2021.07.28 |
| [정리] DeepFM: A Factorization-Machine based Neural Network for CTR Prediction (0) | 2021.04.17 |



댓글