오토인코더
Unsupervised Learning중 하나로 주로 데이터의 특징을 발견하는 것이 목표인 학습 방법.
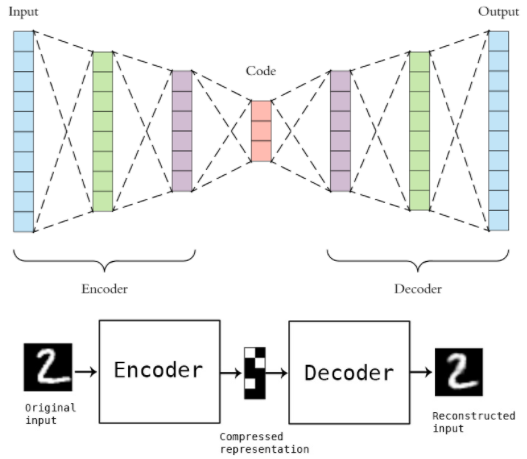
오토인코더는 Input Layer와 Output Layer의 노드 수가 동일한 구조.
인풋 값을 특정 N Factor로 압축 후 이를 다시 잘 복원하도록 학습시킴.
압축 된 부분을 차원축소된 feature로 활용할 수 있음.
-> 이를 Classifier의 인풋으로 사용해 더 나은 성능을 기대할 수 있음.
MNIST
데이터 로드 및 train/test split
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as tf
from sklearn.datasets import fetch_openml
from sklearn.model_selection import train_test_split
mnist = fetch_openml('mnist_784')
mnist.data.shape, mnist.target.shape
X_train, X_test, y_train, y_test = train_test_split(mnist.data, mnist.target, random_state=613)
X_train = X_train.to_numpy('float32')/255.
y_train = y_train.to_numpy('float32')
X_test = X_test.to_numpy('float32')/255.
y_test = y_test.to_numpy('float32')
# denoise autoencoder 구현을 위해 noise 데이터 생성
np.random.seed(613)
X_train_noise = X_train+.3*np.random.normal(loc=.0, scale=1., size=X_train.shape)
X_test_noise = X_test+.3*np.random.normal(loc=.0, scale=1., size=X_test.shape)
X_train_noise = np.clip(X_train_noise, 0., 1.)
X_test_noise = np.clip(X_test_noise, 0., 1.)데이터 확인
# 이미지 표시해줄 함수 선언
def show_imgs(up,down):
plt.style.use('fivethirtyeight')
plt.figure(figsize=(30,6))
plt.gray()
n_img=10
for i in range(n_img):
plt.subplot(2,n_img,i+1)
plt.imshow(np.reshape(up[i], (28,28)))
plt.axis('off')
plt.subplot(2,n_img, n_img+i+1)
plt.imshow(np.reshape(down[i], (28,28)))
plt.axis('off')
show_img(X_train, X_train_noise)
이와 같은 데이터를 0~9까지 올바르게 분류하는 것이 본 데이터의 목적
NN model
epochs = 100
batch_size = 64
early_stopping = EarlyStopping(monitor='val_loss', patience=10)
class Neural(Model):
def __init__(self):
super(Neural, self).__init__()
self.layer1 = Dense(512, activation='relu')
self.layer2 = Dense(256, activation='relu')
self.layer3 = Dense(128, activation='relu')
self.layer4 = Dense(64, activation='relu')
self.layer5 = Dense(10, activation='softmax')
self.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['acc'])
def call(self, inputs):
x = self.layer1(inputs)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
return self.layer5(x)with tf.device('GPU:0'):
model = Neural()
model.fit(X_train,y_train,
epochs=epohcs, batch_size=batch_size,
validation_data=(X_test,y_test),
callbacks=[early_stopping])Result
# Normal Test Data에 대한 결과
print(classification_report(model.predict(X_test).argmax(axis=1),y_test, digits=4))
print(accuracy_score(model.predict(X_test).argmax(axis=1),y_test))
'''
precision recall f1-score support
0 0.9937 0.9846 0.9891 1758
1 0.9935 0.9890 0.9912 1999
2 0.9786 0.9809 0.9797 1677
3 0.9682 0.9882 0.9781 1697
4 0.9831 0.9797 0.9814 1724
5 0.9816 0.9576 0.9695 1674
6 0.9822 0.9857 0.9840 1684
7 0.9873 0.9755 0.9814 1916
8 0.9650 0.9792 0.9721 1634
9 0.9654 0.9799 0.9726 1737
accuracy 0.9802 17500
macro avg 0.9799 0.9800 0.9799 17500
weighted avg 0.9803 0.9802 0.9802 17500
0.9801714285714286
'''
# Noised Test Data에 대한 결과
print(classification_report(model.predict(X_test_noise).argmax(axis=1),y_test, digits=4))
print(accuracy_score(model.predict(X_test_noise).argmax(axis=1),y_test))
'''
precision recall f1-score support
0 0.9713 0.9641 0.9677 1755
1 0.2553 0.9883 0.4058 514
2 0.9774 0.5697 0.7198 2884
3 0.8493 0.8287 0.8389 1775
4 0.6385 0.9691 0.7698 1132
5 0.9326 0.8322 0.8796 1830
6 0.7698 0.9760 0.8607 1333
7 0.8732 0.8793 0.8762 1880
8 0.8938 0.5012 0.6423 2957
9 0.6982 0.8549 0.7687 1440
accuracy 0.7772 17500
macro avg 0.7860 0.8363 0.7729 17500
weighted avg 0.8519 0.7772 0.7859 17500
0.7772
'''Autoencoder
class Autoencoder(Model):
def __init__(self):
super(Autoencoder, self).__init__()
self.encoder = Sequential([
Dense(256, activation='relu'),
Dense(128, activation='relu'),
Dense(64, activation='relu')
])
self.decoder = Sequential([
Dense(128, activation='relu'),
Dense(256, activation='relu'),
Dense(784, activation='sigmoid')
])
self.compile(optimizer='adam', loss='binary_crossentropy')
def call(self, inputs):
encoded = self.encoder(inputs)
decoded = self.decoder(encoded)
return decoded
with tf.device('GPU:0'):
autoencoder = Autoencoder()
autoencoder.fit(X_train_noise, X_train,
epochs=epochs, batch_size=batch_size,
validation_data=(X_test_noise, X_test),
callbacks=[early_stopping])Autoencoding 된 데이터 확인
show_imgs(X_train_noise, autoencoder.predict(X_train_noise))
NN model with Autoencoder
denoised = autoencoder.predict(X_test_noise)
print(classification_report(model.predict(denoised).argmax(axis=1),y_test, digits=4))
print(accuracy_score(model.predict(denoised).argmax(axis=1),y_test))
'''
precision recall f1-score support
0 0.9902 0.9852 0.9877 1751
1 0.9930 0.9777 0.9853 2021
2 0.9691 0.9778 0.9734 1666
3 0.9567 0.9736 0.9651 1702
4 0.9692 0.9720 0.9706 1713
5 0.9749 0.9420 0.9582 1690
6 0.9751 0.9862 0.9807 1671
7 0.9815 0.9582 0.9697 1939
8 0.9415 0.9696 0.9553 1610
9 0.9416 0.9557 0.9486 1737
accuracy 0.9698 17500
macro avg 0.9693 0.9698 0.9694 17500
weighted avg 0.9700 0.9698 0.9698 17500
0.9697714285714286
'''일반 데이터로 train 시킨 NN 모델에 적용시에도 잘 동작함.
'ML' 카테고리의 다른 글
| Basic RNN/LSTM cell implementation (0) | 2021.09.10 |
|---|---|
| seq2seq + attention 이란? (0) | 2021.08.17 |
| RNN, LSTM ? (0) | 2021.08.16 |
| [Tensorflow 2.x] 기초 (0) | 2021.08.13 |
| [정리] DeepFM: A Factorization-Machine based Neural Network for CTR Prediction (0) | 2021.04.17 |



댓글